{kind=link}
Google DeepMind’s Genie is a generative mannequin that interprets easy photographs or textual content prompts into dynamic, interactive worlds.
Genie was skilled on an in depth dataset of over 200,000 hours of in-game video footage, together with gameplay from 2D platformers and real-world robotics interactions.
This huge dataset allowed Genie to grasp and generate the physics, dynamics, and aesthetics of quite a few environments and objects.
The finalized mannequin, documented in a analysis paper, accommodates 11 billion parameters to generate interactive digital worlds from both photographs in a number of codecs or textual content prompts.
So, you would feed Genie a picture of your lounge or backyard and switch it right into a playable 2D platform degree.
Or scribble a 2D setting on a bit of paper and convert it right into a playable recreation setting.
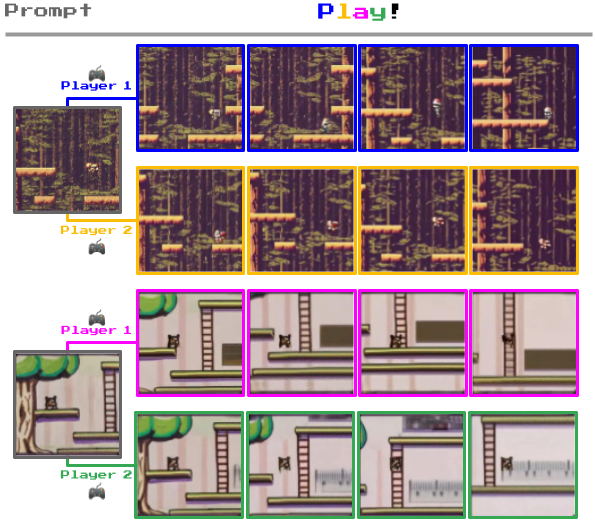
What units Genie other than different world fashions is its capacity to allow customers to work together with the generated environments on a frame-by-frame foundation.
For instance, under, you’ll be able to see how Genie takes pictures of real-world environments and turns them into 2D recreation ranges.

How Genie works
Genie is a “foundation world model” with three key parts: a spatiotemporal video tokenizer, an autoregressive dynamics mannequin, and a easy, scalable latent motion mannequin (LAM).
Right here’s the way it works:
- Spatiotemporal transformers: Central to Genie are spatiotemporal (ST) transformers, which course of sequences of video frames. Not like conventional transformers that deal with textual content or static photographs, ST transformers are designed to grasp the development of visible knowledge over time, making them ultimate for video and dynamic setting era.
- Latent Motion Mannequin (LAM): Genie understands and predicts actions inside its generated worlds by the LAM. This infers the potential actions that would happen between frames in a video, studying a set of “latent actions” straight from the visible knowledge. This allows Genie to regulate the development of occasions in interactive environments, regardless of the absence of specific motion labels within the coaching knowledge.
- Video tokenizer and dynamics mannequin: To handle video knowledge, Genie employs a video tokenizer that compresses uncooked video frames right into a extra manageable format of discrete tokens. Following tokenization, the dynamics mannequin predicts the following set of body tokens, producing subsequent frames within the interactive setting.
The DeepMind group defined of Genie, “Genie could enable a large amount of people to generate their own game-like experiences. This could be positive for those who wish to express their creativity in a new way, for example, children who could design and step into their own imagined worlds.”
In a aspect experiment, when introduced with movies of actual robotic arms participating with real-world objects, Genie demonstrated an uncanny capacity to decipher the actions these arms might carry out. This demonstrates potential makes use of in robotics analysis.
Tim Rocktäschel from the Genie group described Genie’s open-ended potential: “It is hard to predict what use cases will be enabled. We hope projects like Genie will eventually provide people with new tools to express their creativity.”
DeepMind was aware of the dangers of releasing this basis mannequin, stating within the paper, “We have chosen not to release the trained model checkpoints, the model’s training dataset, or examples from that data to accompany this paper or the website.”
“We would like to have the opportunity to further engage with the research (and video game) community and to ensure that any future such releases are respectful, safe and responsible.”
Utilizing video games to simulate real-world purposes
DeepMind has used video video games for a number of machine studying tasks.
For instance, in 2021, DeepMind constructed XLand, a digital playground for testing reinforcement studying (RL) approaches for generalist AI brokers. Right here, AI fashions mastered cooperation and problem-solving by performing duties akin to transferring obstacles in open-ended recreation environments.
Then, simply final month, SIMA (Scalable, Instructable, Multiworld Agent) was designed to grasp and execute human language directions throughout totally different video games and eventualities.
SIMA was skilled utilizing 9 video video games requiring totally different ability units, from fundamental navigation to piloting automobiles.
Recreation environments supply a controllable, scalable sandbox for coaching and testing AI fashions.
DeepMind’s gaming experience extends to 2014-2015, once they developed an algorithm to defeat people in video games like Pong and Area Invaders, to not point out AlphaGo, which defeated professional participant Fan Hui on a full-sized 19×19 board.