{kind=link}
HyperWrite founder and CEO Matt Shumer introduced that his new mannequin, Reflection 70B, makes use of a easy trick to resolve LLM hallucinations and delivers spectacular benchmark outcomes that beat bigger and even closed fashions like GPT-4o.
Shumer collaborated with artificial information supplier, Glaive, to create the brand new mannequin which is predicated on Meta’s Llama 3.1-70B Instruct mannequin.
Within the launch announcement on Hugging Face, Shumer stated. “Reflection Llama-3.1 70B is (currently) the world’s top open-source LLM, trained with a new technique called Reflection-Tuning that teaches a LLM to detect mistakes in its reasoning and correct course.”
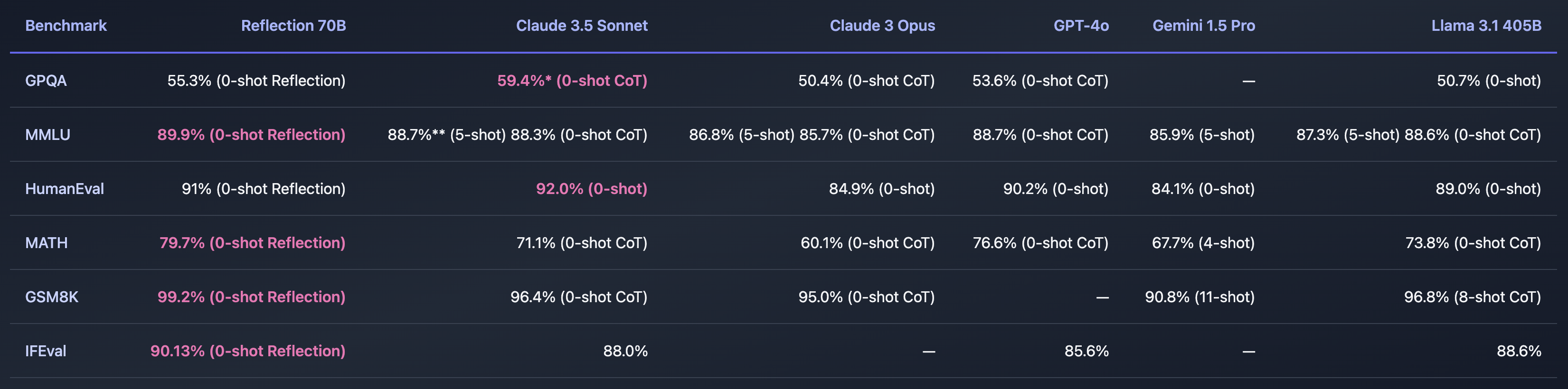
If Shumer discovered a strategy to resolve the problem of AI hallucinations then that might be unimaginable. The benchmarks he shared appear to point that Reflection 70B is approach forward of different fashions.
The mannequin’s title is a reference to its means to self-correct throughout inference. Shumer doesn’t give an excessive amount of away however explains that the mannequin displays on its preliminary reply to a immediate and solely outputs it as soon as happy that it’s appropriate.
Shumer says {that a} 405B model of Reflection is within the works and can blow different fashions, together with GPT-4o away when it’s unveiled subsequent week.
Is Reflection 70B a rip-off?
Is that this all too good to be true? Reflection 70B is accessible for obtain on Huging Face however early testers weren’t capable of duplicate the spectacular efficiency Shumer’s benchmarks confirmed.
The Reflection playground let’s you attempt the mannequin out however says that as a consequence of excessive demand the demo is quickly down. The “Count ‘r’s in strawberry” and “9.11 vs 9.9” immediate strategies trace that the mannequin will get these difficult prompts proper. However some customers declare Reflection has been tuned particularly to reply these prompts.

Some customers questioned the spectacular benchmarks. The GSM8K of over 99% seemed particularly suspect.
Hey Matt! That is tremendous fascinating, however I’m fairly stunned to see a GSM8k rating of over 99%. My understanding is that it’s possible that greater than 1% of GSM8k is mislabeled (the right reply is definitely mistaken)!
— Hugh Zhang (@hughbzhang) September 5, 2024
A few of the floor reality solutions within the GSM8K dataset are literally mistaken. In different phrases, the one strategy to rating over 99% on the GSM8K was to offer the identical incorrect solutions to these issues.
After some testing, customers say that Reflection is definitely worse than Llama 3.1 and that it was really simply Llama 3 with LoRA tuning utilized.

In response to the adverse suggestions, Shumer posted a proof on X saying, “Quick update — we re-uploaded the weights but there’s still an issue. We just started training over again to eliminate any possible issue. Should be done soon.”
Shumer defined that there was a glitch with the API and that they had been engaged on it. In the intervening time, he supplied entry to a secret, non-public API in order that doubters might attempt Reflection out whereas they labored on the repair.
And that’s the place the wheels appear to return off, as some cautious prompting appears to indicate the API is admittedly only a Claude 3.5 Sonnet wrapper.
“Reflection API” is a sonnet 3.5 wrapper with immediate. And they’re presently disguising it by filtering out the string ‘claude’.https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
— Joseph (@RealJosephus) September 8, 2024
Subsequent testing reportedly had the API returning outputs from Llama and GPT-4o. Shumer insists the unique outcomes are correct and that they’re engaged on fixing the downloadable mannequin.
Are the skeptics somewhat untimely in calling Shumer a grifter? Possibly the discharge was simply poorly dealt with and Reflection 70B actually is a groundbreaking open-source mannequin. Or possibly it’s one other instance of AI hype to lift enterprise capital from buyers on the lookout for the subsequent large factor in AI.
We’ll have to attend a day or two to see how this performs out.