{kind=link}
Benchmarks are struggling to maintain up with advancing AI mannequin capabilities and the Humanity’s Final Examination mission needs your assist to repair this.
The mission is a collaboration between the Middle for AI Security (CAIS) and AI knowledge firm Scale AI. The mission goals to measure how shut we’re to reaching expert-level AI techniques, one thing current benchmarks aren’t able to.
OpenAI and CAIS developed the favored MMLU (Large Multitask Language Understanding) benchmark in 2021. Again then, CAIS says, “AI systems performed no better than random.”
The spectacular efficiency of OpenAI’s o1 mannequin has “destroyed the most popular reasoning benchmarks,” based on Dan Hendrycks, government director of CAIS.
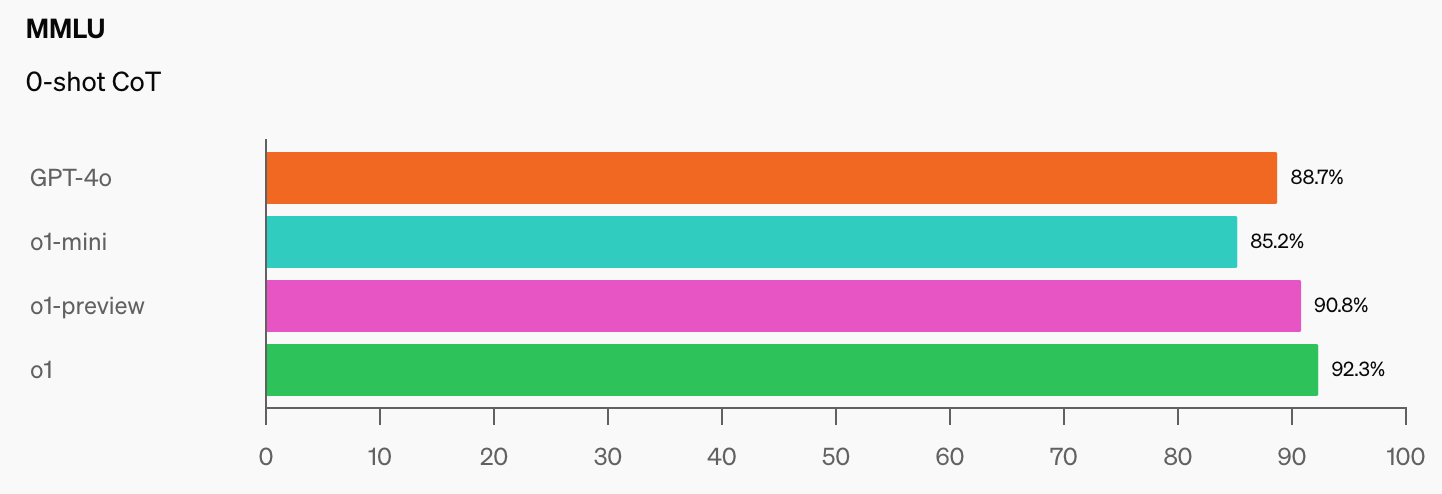
As soon as AI fashions hit 100% on the MMLU, how will we measure them? CAIS says “Existing tests now have become too easy and we can no longer track AI developments well, or how far they are from becoming expert-level.”
Once you see the leap in benchmark scores that o1 added to the already spectacular GPT-4o figures, it received’t be lengthy earlier than an AI mannequin aces the MMLU.
That is objectively true. pic.twitter.com/gorahh86ee
— Ethan Mollick (@emollick) September 17, 2024
Humanity’s Final Examination is asking folks to submit questions that might genuinely shock you if an AI mannequin delivered the right reply. They need PhD degree examination questions, not the ‘how many Rs in Strawberry’ kind that journey up some fashions.
Scale defined that “As existing tests become too easy, we lose the ability to distinguish between AI systems which can ace undergrad exams, and those which can genuinely contribute to frontier research and problem solving.”
You probably have an authentic query that would stump a complicated AI mannequin then you may have your identify added as a co-author of the mission’s paper and share in a pool of $500,000 that shall be awarded to the very best questions.
To offer you an thought of the extent the mission is aiming at Scale defined that “if a randomly selected undergraduate can understand what is being asked, it is likely too easy for the frontier LLMs of today and tomorrow.”
There are just a few fascinating restrictions on the sorts of questions that may be submitted. They don’t need something associated to chemical, organic, radiological, nuclear weapons, or cyberweapons used for attacking crucial infrastructure.
In the event you suppose you’ve obtained a query that meets the necessities then you’ll be able to submit it right here.