{kind=link}
Google’s DeepMind launched Gecko, a brand new benchmark for comprehensively evaluating AI text-to-image (T2I) fashions.
Over the past two years, we’ve seen AI picture turbines like DALL-E and Midjourney develop into progressively higher with every model launch.
Nonetheless, deciding which of the underlying fashions these platforms use is finest has been largely subjective and troublesome to benchmark.
To make a broad declare that one mannequin is “better” than one other isn’t so easy. Totally different fashions excel in varied features of picture era. One could also be good at textual content rendering whereas one other could also be higher at object interplay.
A key problem that T2I fashions face is to observe every element within the immediate and have these precisely mirrored within the generated picture.
With Gecko, the DeepMind researchers have created a benchmark that evaluates the capabilities of T2I fashions equally to how people do.
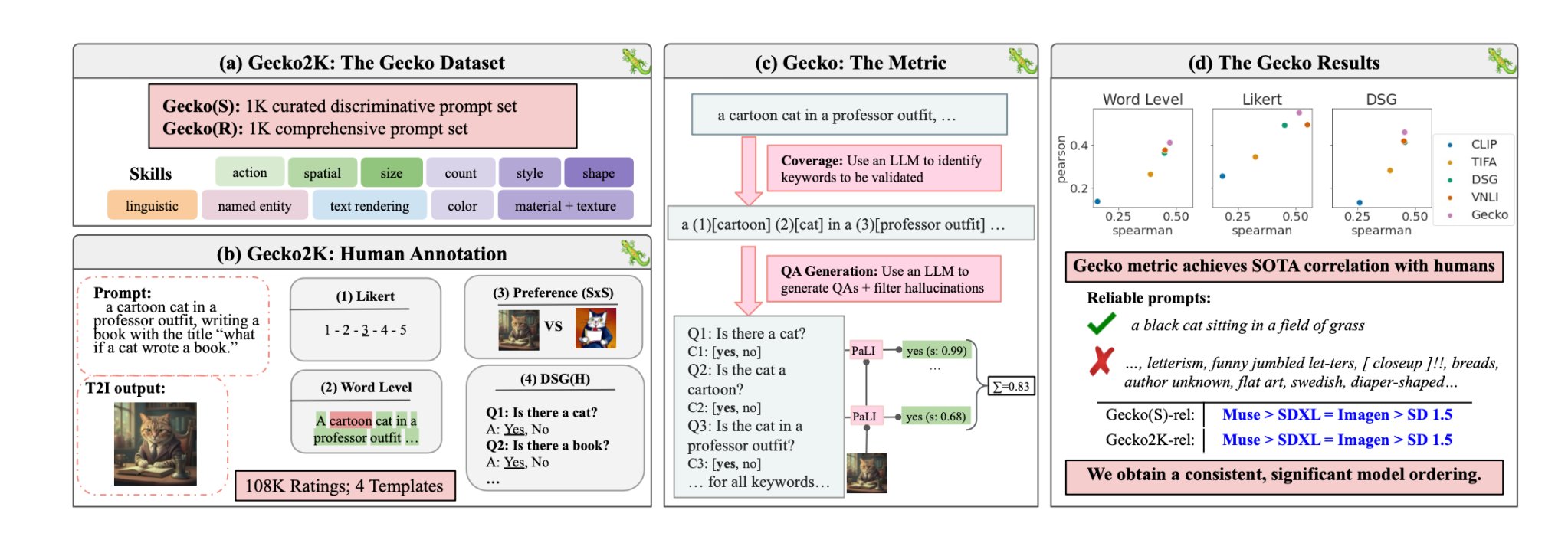
Ability set
The researchers first outlined a complete dataset of expertise related to T2I era. These embody spatial understanding, motion recognition, textual content rendering, and others. They additional broke these down into extra particular sub-skills.
For instance, beneath textual content rendering, sub-skills would possibly embody rendering completely different fonts, colours, or textual content sizes.
An LLM was then used to generate prompts to check the T2I mannequin’s functionality on a selected ability or sub-skill.
This permits the creators of a T2I mannequin to pinpoint not solely which expertise are difficult, however at what stage of complexity a ability turns into difficult for his or her mannequin.
Human vs Auto eval
Gecko additionally measures how precisely a T2I mannequin follows all the main points in a immediate. Once more, an LLM was used to isolate key particulars in every enter immediate after which generate a set of questions associated to these particulars.
These questions could possibly be each easy, direct questions on seen components within the picture (e.g., “Is there a cat in the image?”) and extra complicated questions that check understanding of the scene or the relationships between objects (e.g., “Is the cat sitting above the book?”).
A Visible Query Answering (VQA) mannequin then analyzes the generated picture and solutions the inquiries to see how precisely the T2I mannequin aligns its output picture with an enter immediate.
The researchers collected over 100,000 human annotations the place the individuals scored a generated picture primarily based on how aligned the picture was to particular standards.
The people have been requested to think about a selected side of the enter immediate and rating the picture on a scale of 1 to five primarily based on how effectively it aligned with the immediate.
Utilizing the human-annotated evaluations because the gold customary, the researchers have been in a position to verify that their auto-eval metric “is better correlated with human ratings than existing metrics for our new dataset.”
The result’s a benchmarking system able to placing numbers to particular components that make a generated picture good or not.
Gecko basically scores the output picture in a means that carefully aligns with how we intuitively resolve whether or not or not we’re proud of the generated picture.
So what’s the finest text-to-image mannequin?
Of their paper, the researchers concluded that Google’s Muse mannequin beats Secure Diffusion 1.5 and SDXL on the Gecko benchmark. They might be biased however the numbers don’t lie.