{kind=link}
Apple engineers developed an AI system that resolves complicated references to on-screen entities and consumer conversations. The light-weight mannequin could possibly be a perfect answer for on-device digital assistants.
People are good at resolving references in conversations with one another. Once we use phrases like “the bottom one” or “him” we perceive what the particular person is referring to primarily based on the context of the dialog and issues we will see.
It’s much more troublesome for an AI mannequin to do that. Multimodal LLMs like GPT-4 are good at answering questions on pictures however are costly to coach and require lots of computing overhead to course of every question about a picture.
Apple’s engineers took a special method with their system, referred to as ReALM (Reference Decision As Language Modeling). The paper is price a learn for extra element on their improvement and testing course of.
ReALM makes use of an LLM to course of conversational, on-screen, and background entities (alarms, background music) that make up a consumer’s interactions with a digital AI agent.
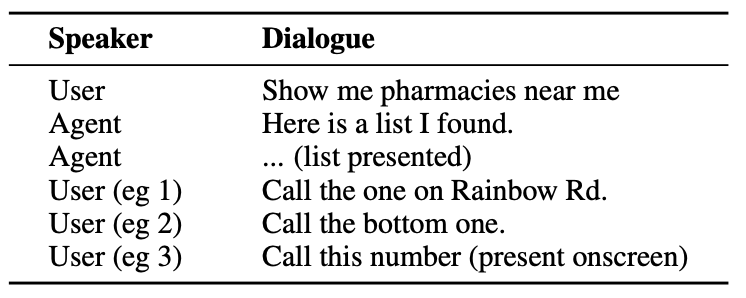
Right here’s an instance of the sort of interplay a consumer may have with an AI agent.
The agent wants to know conversational entities like the truth that when the consumer says “the one” they’re referring to the phone quantity for the pharmacy.
It additionally wants to know visible context when the consumer says “the bottom one”, and that is the place ReALM’s method differs from fashions like GPT-4.
ReALM depends on upstream encoders to first parse the on-screen components and their positions. ReALM then reconstructs the display screen in purely textual representations in a left-to-right, top-to-bottom trend.
In easy phrases, it makes use of pure language to summarize the consumer’s display screen.
Now, when a consumer asks a query about one thing on the display screen, the language mannequin processes the textual content description of the display screen somewhat than needing to make use of a imaginative and prescient mannequin to course of the on-screen picture.
The researchers created artificial datasets of conversational, on-screen, and background entities and examined ReALM and different fashions to check their effectiveness in resolving references in conversational methods.
ReALM’s smaller model (80M parameters) carried out comparably with GPT-4 and its bigger model (3B parameters) considerably outperforms GPT-4.
ReALM is a tiny mannequin in comparison with GPT-4. Its superior reference decision makes it a perfect alternative for a digital assistant that may exist on-device with out compromising efficiency.
ReALM doesn’t carry out as properly with extra complicated pictures or nuanced consumer requests but it surely may work properly as an in-car or on-device digital assistant. Think about if Siri may “see” your iPhone display screen and reply to references to on-screen components.
Apple has been just a little sluggish out of the blocks, however latest developments like their MM1 mannequin and ReALM present quite a bit is going on behind closed doorways.