{kind=link}
OpenAI didn’t launch any new fashions at its Dev Day occasion however new API options will excite builders who wish to use their fashions to construct highly effective apps.
OpenAI has had a tricky few weeks with its CTO, Mira Murati, and different head researchers becoming a member of the ever-growing listing of former workers. The corporate is underneath rising stress from different flagship fashions, together with open-source fashions which supply builders cheaper and extremely succesful choices.
The brand new options OpenAI unveiled had been the Realtime API (in beta), imaginative and prescient fine-tuning, and efficiency-boosting instruments like immediate caching and mannequin distillation.
Realtime API
The Realtime API is probably the most thrilling new function, albeit in beta. It permits builders to construct low-latency, speech-to-speech experiences of their apps with out utilizing separate fashions for speech recognition and text-to-speech conversion.
With this API, builders can now create apps that permit for real-time conversations with AI, akin to voice assistants or language studying instruments, all by a single API name. It’s not fairly the seamless expertise that GPT-4o’s Superior Voice Mode presents, however it’s shut.
It’s not low-cost although, at roughly $0.06 per minute of audio enter and $0.24 per minute of audio output.
The brand new Realtime API from OpenAI is unimaginable…
Watch it order 400 strawberries by truly CALLING the shop with twillio. All with voice. 🍓🎤 pic.twitter.com/J2BBoL9yFv
— Ty (@FieroTy) October 1, 2024
Imaginative and prescient fine-tuning
Imaginative and prescient fine-tuning throughout the API permits builders to boost their fashions’ capability to know and work together with photographs. By fine-tuning GPT-4o utilizing photographs, builders can create functions that excel in duties like visible search or object detection.
This function is already being leveraged by firms like Seize, which improved the accuracy of its mapping service by fine-tuning the mannequin to acknowledge visitors indicators from street-level photographs.
OpenAI additionally gave an instance of how GPT-4o might generate further content material for a web site after being fine-tuned to stylistically match the location’s current content material.
Immediate caching
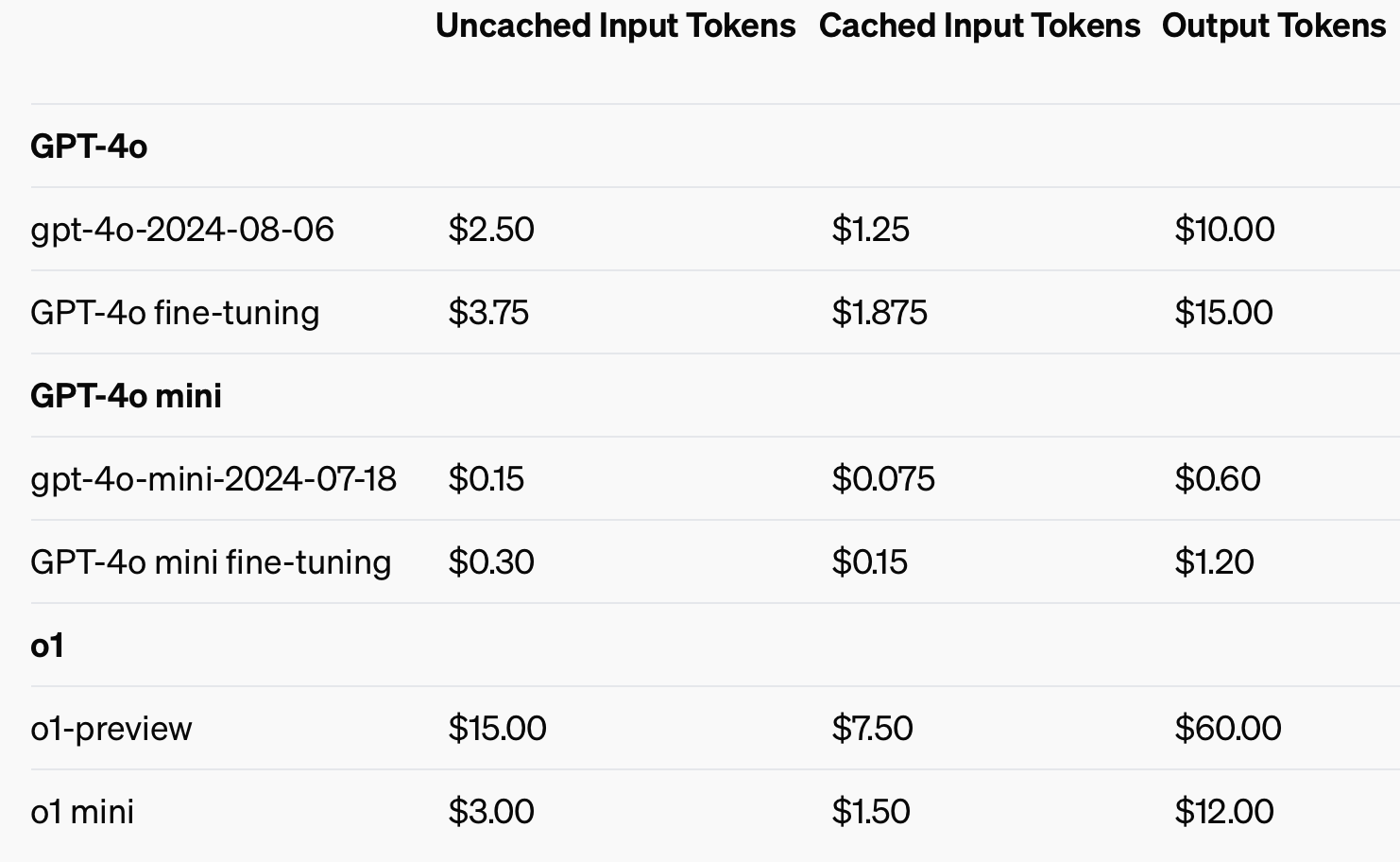
To enhance price effectivity, OpenAI launched immediate caching, a device that reduces the fee and latency of continuously used API calls. By reusing just lately processed inputs, builders can lower prices by 50% and cut back response occasions. This function is very helpful for functions requiring lengthy conversations or repeated context, like chatbots and customer support instruments.
Utilizing cached inputs might save as much as 50% on enter token prices.
Mannequin distillation
Mannequin distillation permits builders to fine-tune smaller, extra cost-efficient fashions, utilizing the outputs of bigger, extra succesful fashions. This can be a game-changer as a result of, beforehand, distillation required a number of disconnected steps and instruments, making it a time-consuming and error-prone course of.
Earlier than OpenAI’s built-in Mannequin Distillation function, builders needed to manually orchestrate totally different elements of the method, like producing information from bigger fashions, getting ready fine-tuning datasets, and measuring efficiency with varied instruments.
Builders can now robotically retailer output pairs from bigger fashions like GPT-4o and use these pairs to fine-tune smaller fashions like GPT-4o-mini. The entire technique of dataset creation, fine-tuning, and analysis might be performed in a extra structured, automated, and environment friendly means.
The streamlined developer course of, decrease latency, and decreased prices will make OpenAI’s GPT-4o mannequin a gorgeous prospect for builders trying to deploy highly effective apps shortly. It will likely be attention-grabbing to see which functions the multi-modal options make doable.